生成式 AI 模型正在迅速進化,並提供無可比擬的精密性與功能。這項技術進展得以讓各產業的企業與開發人員解決複雜的問題,並發掘新商機。不過生成式 AI 模型的成長,也導致訓練、調整與推論方面的要求變得更加嚴苛。過去五年來,生成式 AI 模型的參數每年增加十倍,現今的大型模型具有數千億、甚至數兆項參數,即便使用最專門的系統,仍需要相當長的訓練時間,有時需持續數月才能完成。此外,高效率的 AI 工作負載管理需要一個具備一致性、且由最佳化的運算、儲存、網路、軟體和開發框架所組成的整合式 AI 堆疊。
為解決這些難題,今天我們很高興宣布推出 Cloud TPU v5p,這是 Google 目前功能最強大、擴充能力最佳,且最具有彈性的 AI 加速器。長久以來,TPU 一直是用來訓練、服務 AI 支援的產品之基礎,這類產品包含 YouTube、Gmail、Google 地圖、Google Play 及 Android。事實上,Google 日前宣布推出功能最強大、最通用的 AI 模型 Gemini 便是使用 TPU 進行訓練與服務。
此外,我們也宣布推出 Google Cloud AI Hypercomputer。AI Hypercomputer 是 Google Cloud 的突破性超級電腦架構,採用整合式系統,並結合了效能最佳化硬體、開放式軟體、領先機器學習架構及靈活彈性的消費模式。傳統上通常是以零碎的方式,在元件層級進行增強以處理要求嚴苛的 AI 工作負載需求,而這可能導致效率不佳,或出現瓶頸。相較之下,AI Hypercomputer 採用系統層級的協同設計來提升 AI 訓練、調整與服務的效率與生產力。
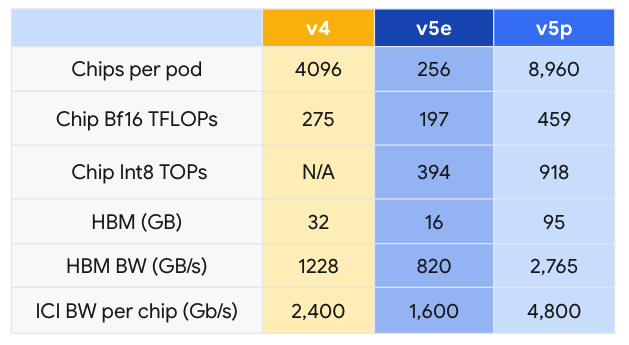
上個月,我們宣布全面推出 Cloud TPU v5e。相較於上一代的 TPU v4,Cloud TPU v5e 的性價比提高了 2.3 倍,是我們目前最具成本效益的 TPU。而 Cloud TPU v5p,則是我們目前功能最強大的 TPU。每個 TPU v5p Pod 均由 8,960 個晶片組成,透過 我們頻寬最高的晶片間互連網路(Inter-chip Interconnect, ICI)相連,採用 3D 環面拓撲,提供每晶片 4,800 Gbps 的速度。相較於 TPU v4,TPU v5p 每秒的浮點運算次數(FLOPS)提高 2 倍以上,高頻寬記憶體(High-bandwidth Memory, HBM)則增加 3 倍。
TPU v5p 專為效能、彈性與大規模作業而設計,相較於前一代的 TPU v4,TPU v5p 訓練大型 LLM 模型的速度提升 2.8 倍。不僅如此,若搭配第二代 SparseCores,TPU v5p 訓練嵌入密集模型的速度較 TPU v4 快 1.9 倍[1]。
資料來源:Google 內部資料,截至 2023 年 11 月, GPT3-175B的所有數據均以晶片為單位完成標準化作業
資料來源:TPU v5e 資料來自 MLPerf™ 3.1 Training Closed 的 v5e 結果;TPU v5p 及 v4 數據來自 Google 內部執行的訓練作業。截至 2023 年 11 月,GPT-3 1750 億參數模型的所有數據均以每晶片 seq-len=2048 為單位完成標準化,並以 TPU v4:$3.22 美元/晶片/小時、TPU v5e: $1.2 美元/晶片/小時、以及 TPU v5p:$4.2 美元/晶片/小時的公開定價顯示每美元相對的效能。
TPU v5p 不僅效能更優異,就每 Pod 的總可用 FLOPS 而言,TPU v5p 的擴充能力較 TPU v4 高 4 倍,且 TPU v5p 每秒的浮點運算次數(FLOPS)是 TPU v4 的兩倍,並在單一 Pod 中提供兩倍的晶片,可大幅提升訓練速度的相對效能。
達到規模和速度是必要,但並不足以滿足現代 AI/ML 應用程式與服務的需求。軟硬體元件必須相輔相成,組成一個易於使用、安全可靠的整合式運算系統。Google 已針對此問題投入數十年的時間進行研發,而 AI Hypercomputer 正是我們的心血結晶。此系統集結了多種能協調運作的技術,能以最佳方式來執行現代 AI 工作負載。
效能最佳化硬體:AI Hypercomputer 以超大規模資料中心基礎架構為建構基礎,採用高密度足跡、水冷技術以及我們 Jupiter 資料中心網路技術,在運算、儲存與網路功能上皆能提供最佳效能。上述一切均仰賴以效率為核心的技術,不僅採用潔淨能源,並深耕水資源管理,協助我們朝無碳未來邁進。
開放式軟體:透過 AI Hypercomputer,開發人員即可使用開放式軟體存取 Google 的效能最佳化硬體,利用這些硬體調整、管理及動態調度管理 AI 訓練與推論的工作負載。
廣泛支援多種熱門機器學習架構(例如 JAX、TensorFlow 與 PyTorch),全可立即使用。如要建立複雜的 LLM,JAX 與 PyTorch 均採用 OpenXLA 編譯器。XLA 作為基礎骨幹,提供建立複雜多層式模型的功能 (可參閱 在 Cloud TPU 上使用 PyTorch/XLA 進行 Llama 2 訓練與推論的說明)。XLA 會將廣泛硬體平台的分散式架構調整至最佳狀態,確保各種 AI 用途的模型開發作業既簡單又有效率(可參閱 AssemblyAI 在大規模 AI 語音技術中運用 JAX/XLA 與 Cloud TPU 的說明)。
提供開放且獨特的 Multislice Training及Multihost Inferencing 軟體,分別使擴充、訓練與提供模型的工作負載變得流暢又簡單。若要處理需求嚴苛的 AI 工作負載,開發人員可將晶片數量擴充至數萬個。
深度整合 Google Kubernetes Engine(GKE) 及 Google Compute Engine,已提供有效率的管理資源、一致的作業環境、自動調度資源、自動佈建節點集區、自動查核點、自動續傳,並即時進行故障復原等作業。
靈活彈性的消費模式:AI Hypercomputer 提供廣泛且彈性的動態消費選擇。除了承諾使用折扣(Committed Used Discunts, CUD)、以量計價與現貨價格等傳統選項,AI Hypercomputer 也透過 Dynamic Workload Scheduler 提供專為 AI 工作負載量身打造的消費模式。Dynamic Workload Scheduler 包含兩種消費模式:Flex Start Mode 可取得更多資源,且價格實惠,Calendar Mode 則適用於工作開始時間較容易預測的工作負載。
我們的客戶像是 Salesforce 與 Lightricks 均已採用 Google Cloud 的 TPU v5p 與 AI Hypercomputer 來訓練和服務大型 AI 模型,並發現了其中差異:
「我們持續運用 Google Cloud TPU v5p 來預先訓練 Salesforce 的基礎模型,這些模型將作為特殊用途生產用的核心引擎,我們也發訓練速度有顯著的提升。事實上, Cloud TPU v5p 的運算能力相比前一代的 TPU v4 高出至少 2 倍。此外,我們也非常喜歡使用 JAX ,可輕鬆無縫地從 Cloud TPU v4 轉換到 v5p。我們期待能透過 Accurate Quantized Training(AQT) 程式庫,運用 INT8 精確格式的原生支援來優化我們的模型,進一步提升速度。」- Salesforce 資深研究科學家 Erik Nijkamp
「透過 Google Cloud TPU v5p 出色的效能及充足的記憶體容量,讓我們能成功訓練文字轉換影片的生成式模型,而不必拆分成不同的程序。這種最佳的硬體運用率顯著地加快了每個訓練週期,使我們能迅速執行一系列的實驗。能在每個實驗中快速完成模型訓練的能力促進了快速迭代,為我們的研究團隊在生成式 AI 這個競爭激烈的領域帶來寶貴優勢。」- Lightricks 核心生成式 AI 研究團隊主管 Yoav HaCohen 博士
「在我們的早期使用階段,Google DeepMind 及 Google 研究團隊發現,相較於 TPU v4 世代的效能,使用 TPU v5p 晶片的 LLM 訓練工作負載的速度提升了 2 倍。此外,AI Hypercomputer 能為機器學習架構(JAX、PyTorch、TensorFlow)提供強大的支援功能與自動調度管理工具,讓我們在使用 v5p 時能更有效率地進行擴充。搭配第 2 代 SparseCores 時,我們也發現密集嵌入型工作負載 (embeddings-heavy workloads)的效能大幅提升。TPU 是我們之所以可以大規模進行如 Gemini 這種先進模型的研究和工程作業的關鍵。」- Google DeepMind 及 Google 研究首席科學家 Jeff Dean我們一直深信 AI 能協助解決各種棘手難題。直到最近,大規模訓練與提供大型基礎模型的作業對許多組織來說都過於複雜且昂貴。現在透過 Cloud TPU v5p 及 AI Hypercomputer,我們很高興能將我們在 AI 與系統設計領域數十年的研究心血和我們的用戶分享,方便他們以更快、更有效率、更符合成本效益的方式運用 AI 加速創新。
如要申請使用 Cloud TPU v5p 及 AI Hypercomputer,請與 Google Cloud 客戶經理聯繫。若要進一步瞭解 Google Cloud 的 AI 基礎架構,歡迎報名參加 Google Cloud 應用 AI 高峰會。
[1]:MLPerf™ v3.1 Training Closed 的結果顯示多種測試基準。資料日期:2023 年 11 月 8 日;資料來源:mlcommons.org。結果編號:3.1-2004。每美元的效能並非 MLPerf 的評估標準。TPU v4 结果尚未經過 MLCommons 協會驗證。MLPerf™ 名稱和標誌是 MLCommons 協會在美國和其他國家的商標,並保有所有權利,嚴禁未經授權的使用。更多訊息請參閱 www.mlcommons.org
[2]:截至 2023 年 11 月,Google TPU v5e 內部資料:E2E 執行時間(steptime),搜尋廣告預估點擊率 (SearchAds pCTR),每個 TPU 核心批次大小為 16,384,125 個 vp5 晶片。
本文作者:Google Cloud 機器學習、系統和 Cloud AI 副總裁暨總經理 Amin Vahdat






沒有留言 :
張貼留言